비트 바이트 키로바이트
Bit -> Byte -> KByte -> MByte -> GByte -> TByte
1 Bit
Byte = 8Bit
KByte = 1024Byte
MByte = 1024KByte
GByte = 1024MByte
TByte = 1024GByte
2012년 6월 20일 수요일
2012년 6월 19일 화요일
std::string, boost, CString::Format의 printf() 기능 사용 및 구현
기본 사용법
CString
CString str;
str.Format("%s%03d", szSomeVar, nSomeVar);
타입 안정성을 중요시하는 C++ 에서는 안타깝게도 CString의 Format 계열 함수가 제공 되지 않는다.
그래서 버퍼를 잡아 C의 런타임함수인 sprintf 함수를 사용하는수 밖에 없다.
그러나 C++에서는 stream 객체가 있으므로 sprintf 보다 우아(?) 하게 사용 할수 있다.
#include로 사용할수 있으며 input/output/ input&output 버전이 따로 존재한다.
stringstream in & out
ostringstream out
istringstream in
유니 코드 버전은 위의 클래스 네임에 w만 앞쪽에 붙여 주면되고
stringstream 내의 함수 중에 str() 멤버 함수로 string 클래스의 객체와 같이 연동해서 쓸 수 있다.
STL
#include
#include
#include
using namespace std;
ostringstream strStream;
strStream << szSomeVar << setw(3) << setfill('0') << nSomeVar;
string str = strStream.str();
BOOST
#include
#include
std::string someString;
someString = boost::str(boost::format("%s%03d") % szSomeVar % nSomeVar);
CString
CString str;
str.Format("%s%03d", szSomeVar, nSomeVar);
타입 안정성을 중요시하는 C++ 에서는 안타깝게도 CString의 Format 계열 함수가 제공 되지 않는다.
그래서 버퍼를 잡아 C의 런타임함수인 sprintf 함수를 사용하는수 밖에 없다.
그러나 C++에서는 stream 객체가 있으므로 sprintf 보다 우아(?) 하게 사용 할수 있다.
#include
stringstream in & out
ostringstream out
istringstream in
유니 코드 버전은 위의 클래스 네임에 w만 앞쪽에 붙여 주면되고
stringstream 내의 함수 중에 str() 멤버 함수로 string 클래스의 객체와 같이 연동해서 쓸 수 있다.
STL
#include
#include
#include
using namespace std;
ostringstream strStream;
strStream << szSomeVar << setw(3) << setfill('0') << nSomeVar;
string str = strStream.str();
BOOST
#include
#include
std::string someString;
someString = boost::str(boost::format("%s%03d") % szSomeVar % nSomeVar);
CString의 Format에 해당하는 STL 코드와 BOOST 코드
직접 구현하기
1. 코드프로젝트
STL Format
CString의 Format같은 기능을 함수로 구현해 놓은게 있다.
근데 VC6에선 제대로 컴파일이 안된다. 우선 string의 clear는 stlport에는 없다.
2. 권진호님
sprintf 와 string 과의 만남
3. codein.co.kr
4. 본인은 CString의 FromatV함수로 간단히 구현했음. 차라리 CString을 사용하는게 낫지 않냐고 하시면..
내부 구현은 나중에 제대로 테스트후 적용해도 된다. ㅋ
UINT StrPrintf( string& rstr, const char *pFmt, ... )
{
va_list args;
va_start(args, pFmt);
CString csMsg;
csMsg.FormatV(pFmt, args);
rstr = csMsg;
va_end(args);
return rstr.length();
}
1. 코드프로젝트
STL Format
CString의 Format같은 기능을 함수로 구현해 놓은게 있다.
근데 VC6에선 제대로 컴파일이 안된다. 우선 string의 clear는 stlport에는 없다.
2. 권진호님
sprintf 와 string 과의 만남
3. codein.co.kr
#define _MAX_CHARS 8000
int Format(std::string& txt, const TCHAR* szFormat,...)
{
std::vector<TCHAR> _buffer(_MAX_CHARS);
va_list argList;
va_start(argList,szFormat);
#ifdef _UNICODE
int ret = _vsnwprintf(&_buffer[0],_MAX_CHARS,szFormat,argList);
#else
int ret = _vsnprintf(&_buffer[0],_MAX_CHARS,szFormat,argList);
#endif
va_end(argList);
txt.assign(&_buffer[0],ret);
return ret;
}
4. 본인은 CString의 FromatV함수로 간단히 구현했음. 차라리 CString을 사용하는게 낫지 않냐고 하시면..
내부 구현은 나중에 제대로 테스트후 적용해도 된다. ㅋ
UINT StrPrintf( string& rstr, const char *pFmt, ... )
{
va_list args;
va_start(args, pFmt);
CString csMsg;
csMsg.FormatV(pFmt, args);
rstr = csMsg;
va_end(args);
return rstr.length();
}
[원리에 대한 고찰] 동차좌표계(homegeneous Coordinates)
퍼온 자료 : http://www.gpgstudy.com/forum/viewtopic.php?topic=6396 (GPG Study의 Q&A란)
* etds님의 설명 (애니파크)
간단하게 말하면 (x, y, z, w)는 3D상에서 (x/w, y/w, z/w)를 나타내는 것이고,
(3D 프로그래밍을 하는 입장에서 봤을 때) 굳이 w를 넣어서 4차원으로 표현하는 이유는
1. 무한대를 표시할 수 있다. w를 0으로 놓으면 되니까. (w=0이면 point가 아니라 direction이라
고 생각할 수 있다)
2. translation도 행렬의 곱으로 표현할 수 있다.
* 비회원님의 설명
(1,2,3)하고 (2,4,6)하고 다르죠.
근데, 동차좌표계에서는 이걸 같이 할 수 있습니다.
바로 뒤에 w하나를 더 넣는거죠.
(1,2,3,1) = (2,4,6,2)입니다.
프로젝션 매트릭스를 하면 바로 마지막 w에 1이 아닌 값이 나옵니다.
컴은 맨마지막에 이 w로 x,y,z와 자기 자신까지 나눠버립니다.
(2/2,4/2,6/2,2/2)=(1,2,3,1)입니다.
그래서 같은거죠.
이것보다는 왜 이걸 쓰느냐 하는 문제입니다. 그게 더 중요하죠.
프로젝션해보셨으니, 그 이론 중 z로 나눠야 한다는 대목이 있을겁니다.
근데 이걸 매트릭스에 넣으려고 하니까 안되는겁니다.
왜? 제일 쉬운 삼각형 하나만 예로 들어보죠.
삼각형 좌표가 (1,1,1) (10,10,10) (100,100,100)이라고 해봅시다.
이게 프로젝션을 통과하면 정삼각형이 나옵니다. 즉 (1,1,1) (1,1,1) (1,1,1)이 되어야 하거든요.
이걸 매트릭스에 표현해봅시다. 첫번째 점은 통과입니다. (10,10,10)은 나누기 10 하면 되겠군요.
근데 세번째 점은 (100,100,100)은 나누기 100해야됩니다.
스케일을 해야 저 점이 (1,1,1)이 되는데 점마다 나눠야 할 크기가 다릅니다.
그래서 수학자들이 생각햇습니다. 나누는 점이 그때그때 다르면 어떻게 할까?
해결책이 동차좌표입니다. projection._34 = 1.0f로 되어있죠. 한 번 보세요.
그리고 그 projection매트릭스에 (x,y,z,1)를 곱해보세요. 딴 건 몰라도 (?,?,?,z)이렇게 됨을 알
수 있습니다.
그러면 컴은 나중에 이 w를 무조건 1로 만들어야 하니, 저장되어있는 각각 다른 w(=z)로 나누게
되는겁니다.
3D 동차 좌표계
3D에서의 필요한 벡터는 기본적으로 3차원좌표계이다.
이것을 4차원 좌표계로 확장하는데 추가되는 개념이 바로 동차 좌표계이다.
동차좌표는 결국은 4x4 행렬과의 연산 때문에 필요하다.
이동,크기,회전을 모두 담은 행렬은 최소 4x4 행렬일 수밖에 없다.
이 행렬과 정상적인 연산을 하기 위해서는 '벡터도 행렬' 이므로 1x4 또는 4x1형태를 맞춰줘야 한다.
그렇다면 처음부터 끝까지 동차좌표계가 1이면 된다.
게다가 당연히 1이라는 표시만 해주면 되는 기호는 생략 가능한데 굳이 따라다니는 아래와같다.
동차좌표는 방향과 점의 구분시켜준다.
x,y,z(DirextX는 D3DXVECTOR3)의 형태의 3차원 좌표계 구조체는 이게 점인지 방향인지 구분이 모호하기 때문에 동차 좌표계가 포함된 4차원좌표계로 표시하게 되면(0은 방향,1은 위치) 좀 더 그 의미가 확실해진다.
┌ 1 , 0 , 0 , 0 ┐ - x축 벡터
│ 0 , 1 , 0 , 0 │ - y축 벡터
│ 0 , 0 , 1 , 0 │ - z축 벡터
└ 0 , 0 , 0 , 1 ┘ - 이동관련 벡터
각 4개의 동차좌표계를 포함한 벡터(1x4행렬)에서 각 벡터의 동차항은 0,1로 이루어져있다.
0은 방향을 의미하는 벡터로써 위치,방향으로서 서로 다른 벡터인지 구분 가능하다.
(방향벡터가 방향이 같고 위치가 다르다라는 것은 확대 또는 축소인 상태이다.)
1은 위치를 의미하는 벡터로써 위치가 서로 다른 벡터인지 구분가능하다.
그러므로,
0의 동차항을 가지고 있는 벡터는 확대,축소(크기변화),방향변경(방향변화) 가능하고
1의 동차항을 가지고 있는 벡터는 이동(위치변화)가 가능하다.
0의 동차항을 가지고 있는 벡터 1행~3행, 1의 동차항을 가지고 있는 벡터 4행
결국 동차좌표계가 0이면 방향변화,크기변화라고 표현 할 수 있지만 위치변화라고는 말할 수 없다.
동차좌표계가 1이면 위치변화 라고 표현할 수 있지만 방향이나 크기변화라고는 말할 수 없다.
동차좌표는 투영행렬과의 연산에서 특별한 의미를 가진다.
투영행렬은 3D차원의 공간을 2차원의 공간으로 변환시킨다.
그 과정에서 시점으로부터 보이는 점(vector)들의 위치가 중요한게 아니라 결국 시점으로부터의 방향이 중요하다게 된다.

type A는 투영행렬에 대한 이론을 간략하게 설명해 놓은 그림인데 우리가 결국 원하는 것은 3차원의 점들이 2차원인 빨간상자안에 모인 위치들인 것이다.
type B는 점들의 위치보다는 시점으로부터의 방향이 중요한 것이 무슨 말인지 이해하기 위한 그림이다.
위치가 서로 다른 3차원상의 점(vector) A(5,5,?), B(10,10,?), C(100,100,?)이라 생각해 보면 2차원에 투영되는 위치는 결국 하나가 되버린다.
(*z좌표를 ?로 표시한 이유는 정확한 수치로 넣을 경우 오해 소지가 생길 수도 있기 때문이다.)
DirextX기준으로 투영행렬의 마지막에는 카메라 행렬까지 반영한 z값을 가지고 3차원좌표 (a/z,b/z,c/z)의 형태를 가지게 되는데 이 과정을 (a,b,c,z)이렇게 대신함으로써 (a/z,b/z,c/z,1)로 마무리하게 하고 있다.
예를 들어 A의 동차 좌표계가 5이라면 B는 10, C는 100일 것이고 결국은 A,B,C는 같은 2차원 좌표인 (1,1)이라는 픽셀에 찍힐 것이다.
동차좌표라는 것은 마치 '지도의 축소비율'처럼 축소나 확대에 관한 비례개념처럼 보여지기도 하고 이 좌표가 1이 되서 완전한 위치의 형태(변환 끝)로 변형되었는지도 의미하게 된다.
2012년 6월 15일 금요일
std::list, std::vector 순회속도 비교
std::list, std::vector의 속도의 차이가 궁금해서 테스트를 좀 해봤다.
단순히 테스트를 하였고 정밀도는 떨어질수 있지만 대략적인 속도차이를 알고 싶었다.
단순히 vector가 list에 비해서 빠르다라고만 알고있고 구현도 알고만 있었지.
생각해보니 실재로 재어보고 대략 얼마나 차이나나 테스트를 안해봐서
짬나는 시간에 잠깐 테스트를 해봤는데
생각보다 결과는 놀라웠다.
std::list
std::vector
각각의 컨테이너에 value값은 동일하게 넣고
std::list
while(iter != kList.end())
{
int i = *iter;
++iter;
}
for(unsigned int ui = 0 ; ui < kArray.size() ; ++ui)
{
int i = kArray[ui];
}
결과는
- Element 순회 속도는 리스트가 벡터의 비해 6배 느리다
Element의 갯수가 작을수록 차이는 크고 클수록 그 차이는 6.8배의 차이가 난다.
1000개 이상에서는 거의 6.8배에서 크게 변화가 없다.
1000개 이하에서는 차이가 더 벌어지고
최대 14배의 차이가 난다.
1개 -> 15배
10개 -> 9.8배
100개 -> 6.9배
생각보다 많이 나는구나.... 라고 생각을 하게 되었다.
물론 대략 느리다 라고 알고 있어서 될수 있다면 vector를 사용하지만 추가/삭제가 많은 곳에서는
list를 많이 사용했다.
물론 전에도 그랬지만 가끔 vector선호하기도 해서 사용하기도 했지만..
앞으로 더 주의를 기울일 생각이다.
2012년 6월 11일 월요일
C++ 문자열 처리함수
| 문자열함수 |
함수종류
|
함수표기
|
결과형
|
의 미
|
| atoi | atoi(s) | int | 문자열 s를 정수로 표현 | |
| atof | atof(s) | double | 문자열 s를 실수(double)형으로 변환 | |
| atol | atol(s) | long | 문자열 s를 배정도(long)형으로 변환 | |
| strcat | strcat(s1,s2) | char | 문자열 s2를 s1에 연결 | |
| strcmp | strcmp(s1,s2) | char | s1과 s2를 비교 ( s1>s2 -> 1 s1=s2 -> 0 s1 | |
| strchr | strchr(s,c) | char | 문자열 s에서 문자 c의 위치를 구함 | |
| strlen | strlen(s) | char | 문자열의 길이를 구함 | |
| strcpy | strcpy(s1,s2) | char | 문자열 s2를 s1에 복사 | |
| strrev | strrev(s) | char | 문자열을 역으로 변환 | |
| strset | strset(s,c) | char | 문자열 s를 c로 지정한 문자로 변환 | |
| strupr | strupr(s) | char | 문자열 s의 소문자를 대문자로 변환 | |
| strlwr | strlwr(s) | char | 문자열 s의 대문자를 소문자로 변환 | |
| tolower | tolower(c) | int | 단일문자 c를 소문자로 변환 | |
| toupper | toupper(c) | int | 단일문자 c를 대문자로 변환 | |
| 문자검사함수 | Isdigit | isdigit(c) | 문자 c가 0~9 사이 숫자이면 참 | |
| islower | islower(c) | 문자 c가 소문자이면 참 | ||
| isupper | isupper(c) | 문자 c가 대문자이면 참 | ||
| isspace | isspace(c) | 문자 c가 공백이면 참 | ||
| isxdigit | isxdigit(c) | 숫자 c가 16진 문자이면 참 |
Visual C++ 2008 멀티프로세스 컴파일 옵션

Visual C++ 컴파일러 옵션
/MP(여러 프로세스로 빌드)
/MP 옵션은 명령줄에서 소스 파일을 컴파일하는 총 시간을 줄일 수 있습니다. /MP 옵션을 사용하면 컴파일러가 자체의 복사본 하나 이상을 각각 개별 프로세스로 만듭니다. 그런 다음 이러한 복사본에서 소스 파일을 동시에 컴파일합니다. 따라서 소스 파일을 빌드하는 총 시간이 상당히 줄 수 있습니다.
/MP[processMax]
 설명
설명
/MP 컴파일러 옵션은 여러 파일을 컴파일할 때 빌드 시간을 상당히 줄일 수 있습니다. 빌드 시간을 줄이기 위해 컴파일러에서는 자체의 복사본을 최대 processMax개 만든 다음 이러한 복사본을 사용하여 소스 파일을 동시에 컴파일합니다. /MP 옵션은 컴파일에 적용되지만 링크나 링크 타임 코드 생성에는 적용되지 않습니다. 기본적으로 /MP 옵션은 해제되어 있습니다.
빌드 시간 개선은 컴퓨터의 프로세서 수, 컴파일할 파일의 수 및 I/O 용량과 같은 시스템 리소스의 가용성에 달려 있습니다. /MP 옵션을 테스트하여 특정 프로젝트를 빌드할 최상의 설정을 결정할 수 있습니다. 결정을 내리는 데 도움이 필요하면 지침을 참조하십시오.
호환되지 않는 옵션 및 언어 기능
/MP 옵션은 일부 컴파일러 옵션 및 언어 기능과 호환되지 않습니다. 호환되지 않는 컴파일러 옵션을 /MP 옵션과 함께 사용하면 경고 D9030이 표시되고 /MP 옵션은 무시됩니다. 호환되지 않는 언어 기능을 사용하면 오류 C2813이 표시되고 현재 컴파일러 경고 수준 옵션에 따라 컴파일러가 종료되거나 계속됩니다.
| 참고: |
|---|
대부분의 옵션이 호환되지 않은데, 그 이유는 이러한 옵션이 허용될 경우 동시에 실행되는 컴파일러에서 해당 출력을 콘솔이나 특정 파일에 동시에 쓰기 때문입니다. 따라서 출력이 혼합되거나 왜곡됩니다. 옵션을 조합하여 사용하면 성능이 악화되는 경우도 있습니다.
|
다음 표에는 /MP 옵션과 호환되지 않는 컴파일러 옵션 및 언어 기능이 나와 있습니다.
진단 메시지
/MP 옵션과 호환되지 않는 옵션이나 언어 기능을 지정하면 진단 메시지가 표시됩니다. 다음 표에는 이러한 메시지와 컴파일러 동작이 나와 있습니다.
진단 메시지
|
Description
|
컴파일러 동작
|
|---|---|---|
#import! 지시문은/MP 옵션과 호환되지 않습니다.
|
컴파일러 경고 수준 옵션이 달리 지정된 경우를 제외하고는 컴파일이 종료됩니다.
| |
processMax 인수에 잘못된 값을 지정했습니다.
|
컴파일러에서 잘못된 값을 무시하고 값이 1인 것으로 간주합니다.
| |
지정한 옵션이 /MP와 호환되지 않습니다.
|
컴파일러에서 /MP 옵션을 무시합니다.
|
지침
성능 측정
총 빌드 시간을 사용하여 성능을 측정할 수 있습니다. 실제 시간으로 빌드 시간을 측정할 수도 있고 빌드가 시작하는 시간과 정지하는 시간 사이의 차이를 계산하는 소프트웨어를 사용할 수도 있습니다. 컴퓨터에 프로세서가 여러 개인 경우 실제 시간이 소프트웨어 시간 측정보다 더 정확한 결과를 생성할 수 있습니다.
유효 프로세서
컴퓨터에는 실제의 각 프로세서에 대해 하나 이상의 가상 프로세서(유효 프로세서라고도 함)가 있을 수 있습니다. 각 실제 프로세서에는 하나 이상의 코어가 있을 수 있으며 운영 체제에서 코어에 대해 하이퍼스레드를 사용하도록 설정하는 경우 각 코어가 두 개의 가상 프로세서로 표시됩니다.
예를 들어 컴퓨터에 한 개의 코어를 포함하는 한 개의 실제 프로세서가 있고 하이퍼스레딩을 사용할 수 없는 경우 컴퓨터에는 한 개의 유효 프로세서가 있습니다. 이와 달리 컴퓨터에 두 개의 실제 프로세서가 있고 각각에 두 개의 코어가 있으며 모든 코어에서 하이퍼스레딩을 사용할 수 있는 경우 컴퓨터에는 8개의 유효 프로세서가 있습니다. 즉, 2개의 실제 프로세서 x 실제 프로세서당 2개의 코어 x 하이퍼스레딩으로 인한 코어당 2개의 유효 프로세서에 따라 유효 프로세서가 8개가 됩니다.
/MP 옵션에서 processMax 인수를 생략하면 컴파일러가 운영 체제에서 유효 프로세서 수를 가져온 다음 유효 프로세서당 한 개의 프로세스를 만듭니다. 그러나 컴파일러는 특정 프로세서에서 실행되는 프로세스를 확인할 수 없으므로 운영 체제에서 이러한 결정을 내립니다.
프로세스 수
컴파일러에서는 소소 파일을 컴파일하는 데 사용할 프로세스의 수를 계산합니다. 이 값은 명령줄에서 지정하는 소스 파일 수와 /MP 옵션에서 명시적 또는 암시적으로 지정하는 프로세스 수 중 작은 값입니다. /MP 옵션의 processMax 인수를 지정하는 경우 최대 프로세스 수를 명시적으로 설정할 수 있습니다. 또는 processMax 인수를 생략하는 경우 기본값 즉, 컴퓨터의 유효 프로세서 수와 동일한 값을 사용할 수 있습니다.
예를 들어 다음과 같은 명령줄을 지정하는 경우를 가정합니다.
cl /MP7 a.cpp b.cpp c.cpp d.cpp e.cpp
이 경우 5개의 소스 파일과 최대 7개의 프로세스 중 작은 값이 5개이므로 컴파일러에서 5개의 프로세스를 사용합니다. 또는 컴퓨터에 2개의 유효 프로세서가 있고 다음 명령줄을 지정하는 경우를 가정합니다.
cl /MP a.cpp b.cpp c.cpp
이 경우 운영 체제는 2개의 프로세서를 보고하므로 컴파일러는 해당 계산에서 2개의 프로세스를 사용합니다. 따라서 컴파일러에서는 2개의 프로세스와 3개의 소스 파일 중 작은 값인 2개의 프로세스로 빌드를 실행합니다.
소스 파일 및 빌드 순서
소스 파일은 명령줄에서 표시되는 것과 같은 순서로 컴파일되지 않을 수 있습니다. 컴파일러의 복사본을 포함하는 프로세스 집합은 컴파일러에서 만들지만 각 프로세스가 실행되는 때를 예약하는 것은 운영 체제입니다. 따라서 소스 파일이 특정 순서로 컴파일되리라고 보장할 수 없습니다.
소스 파일은 컴파일하는 데 사용할 수 있는 프로세스가 있을 때 컴파일됩니다. 파일 수가 프로세스보다 많은 경우에는 사용 가능한 프로세스에서 첫 번째 파일 집합을 컴파일합니다. 프로세스에서 이전 파일의 처리를 마치고 나머지 파일 중 하나를 작업할 수 있게 되면 나머지 파일을 처리합니다.
명령줄에서 같은 소스 파일을 여러 번 지정하지 마십시오. 예를 들어 도구에서 프로젝트의 종속성 정보를 기반으로 하는 makefile을 자동으로 만드는 경우 이런 문제가 발생할 수 있습니다. /MP 옵션을 지정하지 않으면 컴파일러에서는 파일 목록을 순차적으로 처리하고 각 파일 항목을 다시 컴파일합니다. 그러나 /MP 옵션을 지정하면 여러 컴파일러에서 같은 파일을 동시에 컴파일할 수 있습니다. 따라서 여러 컴파일러에서 같은 출력 파일에 동시에 쓰려고 합니다. 그러면 한 컴파일러가 출력 파일에 대한 쓰기 액세스를 단독으로 얻고 다른 컴파일러는 파일 액세스 오류와 함께 실패합니다.
형식 라이브러리(#import!) 사용
컴파일러에서는 /MP 스위치와 함께 #import!를 전처리기 지시문을 사용할 수 없습니다. 가능하면 다음 단계에 따라 이 문제를 해결합니다.
- 여러 소스 파일의 #import! 지시문을 모두 하나 이상의 파일로 이동한 다음 이러한 파일을 /MP 옵션을 사용하지 않고 컴파일합니다. 결과는 생성된 헤더 파일의 집합입니다.
- 나머지 소스 파일에서 생성된 헤더 파일을 지정하는 #include 지시문을 삽입한 다음 /MP 옵션을 사용하여 나머지 소스 파일을 컴파일합니다.
Visual Studio 프로젝트 설정
VCBUILD.exe 도구
Visual Studio에서는 VCBUILD.exe 도구를 사용하여 솔루션과 프로젝트를 빌드합니다. VCBUILD.exe 도구는 여러 프로젝트를 동시에 빌드할 수 있고 /MP 컴파일러 옵션은 컴파일 단위를 동시에 빌드할 수 있습니다. 응용 프로그램에 따라 /MP 및 VCBuild 중 하나 또는 모두를 사용하여 솔루션의 빌드 시간을 줄일 수 있습니다.
솔루션 빌드 시간은 부분적으로 빌드를 수행하는 프로세스의 수에 영향을 받습니다. VCBUILD.exe 도구의 /M 옵션은 동시에 빌드할 최대 프로젝트 수를 지정합니다. 마찬가지로 /MP 옵션의 processMax 인수는 동시에 빌드할 최대 컴파일 단위 수를 지정합니다. /M 옵션에서 P개의 프로젝트를 지정하고 /MP 옵션에서 C개의 프로세스를 지정하는 경우 최대 P x C개의 프로세스가 동시에 실행됩니다.
VCBuild 또는 /MP 기술을 사용할지 여부를 결정하기 위한 지침은 다음과 같습니다.
- 프로젝트는 많고 각 프로젝트의 파일은 적은 경우 VCBuild 도구를 사용합니다.
- 프로젝트는 적고 각 프로젝트의 파일은 많은 경우 /MP 옵션을 사용합니다.
- 프로젝트 수와 프로젝트당 파일 수가 짝이 맞는 경우 VCBuild 및 /MP를 모두 사용합니다. 처음에는 /M 옵션을 빌드할 프로젝트 수로 설정하고 /MP 옵션을 컴퓨터의 프로세서 수로 설정합니다. 성능을 측정한 다음 최상의 결과 얻기 위해 설정을 조정합니다. 총 빌드 시간에 만족할 때까지 이 주기를 반복합니다.
/Gm 컴파일러 옵션
기본적으로 프로젝트 빌드에서는 /Gm 컴파일러 옵션(증분 빌드)을 디버그 빌드에는 사용하고 릴리즈 빌드에는 사용하지 않습니다. 따라서 디버그 빌드에서는 /MP 컴파일러 옵션이 기본 /Gm 컴파일러 옵션과 충돌하므로 자동으로 해제됩니다.
2012년 6월 4일 월요일
표준 rand()함수보다 유용한 랜덤 생성 알고리즘 ? MT, WELL [출처] 표준 rand()함수보다 유용한 랜덤 생성 알고리즘 ? MT, WELL
이 글은 게임 개발 포에버에 같이 연재된 글입니다.
안녕하세요. 알콜코더 민군입니다.
현재 제작 중인 게임에서, 랜덤 시드 값을 일치 시켜서, 랜덤 결과를 서로 다른 클라이언트끼리 동기화 시키는 작업을 진행 하였습니다. 랜덤 시드값만 서로 일치시키면, 이후에 생성되는 랜덤 함수의 결과값들은 모두 일치가 되기 때문에, 예전에 스타크래프트와 같은 패키지 게임에서 자주 사용했던 테크닉입니다. ^^;
서로 다른 클라이언트끼리 처음 시드값만 일치 시키면, 이후의 랜덤값은 정해져 있기 때문에, 그 랜덤값을 사용한 이벤트등의 동기화에 사용하는 것이죠.
이런 테크닉은 패키지 게임 시절에는 리플레이 저장이나 네트워크 동기화등에서 상당히 많이 사용하였습니다. 하지만 온라인 게임으로 넘어오면서, 대부분 서버에서 랜덤값을 직접 생성하여 넘겨주기 때문에, 이 테크닉 쓸일이 거의 없었는데… 이번 상황은 랜덤값이 게임의 결과에 전혀 영향을 끼치 않고, 단지 연출에만 영향을 끼치기 때문에 이 테크닉을 사용하기로 하였습니다.
(서버 부담을 줄여달라는 서버쪽의 간절한 요청 때문에.. 아흑..OTL)
(서버 부담을 줄여달라는 서버쪽의 간절한 요청 때문에.. 아흑..OTL)
일반적으로 랜덤 함수라면 C++ 표준 rand() 함수를 사용하게 됩니다. 뭐.. 일반적인 랜덤값을 사용하는 경우에는 사실 이 표준 함수를 사용해도, 별 문제는 없습니다. ^^; 하지만 위와 같은 테크닉을 사용할 때는 rand() 함수를 사용하면 안됩니다!
왜냐하면, C++의 표준 rand() 함수는 아래와 같은 약간의 문제점을 가지고 있습니다.
|

< 즉 이런 기적의 확률이 나올수도 있는거임.. ㅠ.ㅠ >
저의 경우에 문제가 되는 것은 1번이 아니라, 2번입니다. 같은 랜덤 시드값으로 서로 다른 클라이언트에서, 싱크를 맞추기 위해서는 랜덤 호출 횟수가 정확히(!) 일치하여야 합니다! 내가 랜덤함수를 5번 호출했으면, 상대방도 5번 호출해야 같은 결과 값이 나와서 싱크가 일치하게 됩니다.
그런데 만약? 내가 작성한 코드가 아니라 어딘가 다른 코드에서 그것도 한쪽 클라이언트에서만 그 사이에 rand()를 호출하게 되면 어떻게 될까요? 넵. 당연히 그 다음부터는 모든 싱크가 아작이 나게됩니다…
(그리고 이 경우에는 어디서부터 문제가 발생 했는지 찾는 것도 거의 불가능)
전역 함수라는 특징 때문에, 어디서 어떻게 불리울지 모르기 때문에, 언제 호출 횟수가 어긋날지 모른다는 문제가 발생하기 때문에, 랜덤 시드로 씽크를 맞추는 이 테크닉에서는 rand() 함수를 사용하는 것은 불가능 합니다.
(내 코드에서는 절대 그럴리가 없어! 라고 해도… 다른 사람이 작성한 코드에서 과연 부르지 않는다는 보장이 있을까요…)
그래서 따로 랜덤 생성 클래스를 만들어 사용하게 됩니다. 랜덤 클래스를 만들고 그 인스턴스만을 사용하게 되면, 호출 횟수가 어긋나는 문제를 해결할 수 있으니까요. ^^
저의 경우가 바로 이런 경우라서, 랜덤 생성 알고리즘을 한번 찾아 봤습니다. 랜덤 생성 알고리즘은 "난수 생성기(Random Number Generator)", 혹은 "의사 난수 생성기" 등으로 불리웁니다.
(그냥 저는 편의를 위해.. 이후 '랜덤 생성기'라고 칭하겠습니다. 이게 걍 편해요…)
이렇게 따로 랜덤 생성기를 이용해서, 랜덤 생성 클래스를 만들어 사용하면, 위와 같이 코드의 다른곳에서 랜덤값이 불리우는 경우를 제어할 수 있습니다. 물론 그렇다고 랜덤 생성 알고리즘을 혼자 고급 수학책이나 물리책 펴놓고 만들어서 쓰라는 이야기는 아닙니다. 친절하게도 이런 알고리즘은 전문 수학자 분들이 편하게 갖다 쓸수 있도록 편하고도 멋지게 만들어 두었습니다.
(아이구~ 이런 감사할때가….)
이런 랜덤 생성기중에서 가장 유명하고 널리 쓰이는 알고리즘이 바로
[메르센 트위스터(MT.Mersenne Twister)]와[WELL]이라는 랜덤 생성기입니다.
[메르센 트위스터(MT.Mersenne Twister)]와[WELL]이라는 랜덤 생성기입니다.
그리고 이 랜덤 생성기들은 위와 같은 테크닉에 사용할 수 있는 용도 외에도 다음과 같은 뛰어난 장점들을 가지고 있습니다
|
|
메르센 트위스터는 현재도 가장 널리 사용되고 있는 랜덤 생성기입니다. C++에서는 Boost에도
이 MT 랜덤 생성기가 구현 되어 있습니다. 또한 MATLAB, Ruby, Python등의 언어에서도 기본 난수 알고리즘으로 채택되어서 사용 되고 있습니다. 뭐 물론 단점이 없는 건 아니지만, 장점이 훨씬 더 크기 때문에 표준으로 채택이 되었겠죠. ^^
그리고 가장 큰 장점은 특별히 따로 구현하지 않아도, Boost에 포함되어 있기 때문에, Boost만
있다면 바로 사용이 가능하다는 장점이 있습니다. 사용 방법에 관해서는 하단의 참조 링크에서
확인하실 수 있습니다.
있다면 바로 사용이 가능하다는 장점이 있습니다. 사용 방법에 관해서는 하단의 참조 링크에서
확인하실 수 있습니다.
WELL
WELL은 위 MT의 디자이너가 10년후에 고안한 난수 발생 알고리즘 입니다. 그의 주장에 따르면
MT보다 40% 빠르고 코드도 더 간단합니다. WELL은 분포도에 따라서 WELL512, WELL1024,
WELL19947, WELL44497의 종류가 있습니다. 숫자가 클수록 분포도가 높긴 하지만, 게임에서
사용하기엔 512나 1024만으로도 충분할 것 같습니다.
WELL의 구현 코드는 이곳에서 받을 수 있습니다. 실제로 보면 정말 구현은 간단합니다.
아래가 WELL512의 구현 코드입니다.
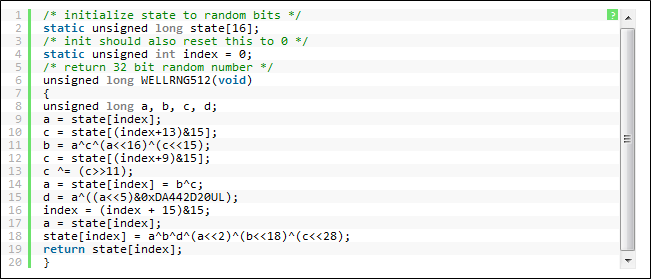
이게 다입니다. Period는 이름 그대로 2^512입니다. 그렇다 해도 일반 PC로 저걸 세는데
10^100년이 걸린다고 하는군요. 초나 분이 아니라 년 말입니다. (googol years라고 부른다고 하는군요)
10^100년이 걸린다고 하는군요. 초나 분이 아니라 년 말입니다. (googol years라고 부른다고 하는군요)
사용법은 위의 state만 적절히 초기화 해주고, 함수를 호출하면 32비트 정수(난수)가 리턴됩니다.
간단한 시물레이터로 두 난수 발생기를 시뮬레이팅 해 보았을 때의 차이를 보여드리겠습니다.

C/C++의 rand함수

WELL512 알고리즘
일반적으로 게임 개발할때는 이런 랜덤 생성기까지 필요 하지 않을지도 모릅니다. 그러나 MMORPG와 같이 랜덤이 게임의 밸런스에 큰 영향을 끼치는 경우에는, 서버 측에서 이런 고성능의 랜덤 생성기가 필요한 경우가 많습니다. 유저나 해커가 랜덤값을 함부로 예측해서는 안되니까요. ^^; 그리고 저의 경우 처럼 랜덤 시드를 이용해서 이벤트 동기화를 맞추는 경우에는 전역 함수인 rand()를 사용할 수 없기 때문에 꼭 이런 랜덤 함수가 별도로 필요합니다. 그런 경우에 굳이 이런 좋은 난수 알고리즘들을 놔두고 새로 짜는 고생은 안하는게 낫겠죠.
(그렇다고 내가 만든 알고리즘이 저것보다 좋을리는 택도 없을 테니…=ㅅ=;)
< 참고 자료 >
위키피디아 : 메르센 트위스터 [한글]
|
피드 구독하기:
글 (Atom)